
支付系统概述
今天我们来探讨支付系统。理解这类系统需要一定生活经验,因为实际并非真让你划账,毕竟你没有金融牌照,无法处理资金。比如上网买衣服,可能要跳转到其他平台付款。用户用信用卡购物时,用户是持卡人,商家是收款方,双方各有对应银行,用户的是发卡行,商家的是收单行,中间还有卡组织,像 Visa 或 MasterCard 这些 card network,负责转发各种支付请求。用户可能有多种银行卡,对应不同发卡行,商家作为收单方也有不同银行账号。若挨个对接,工作量巨大,合规负担重,且银行技术更新慢,可能遇到古老技术栈。所以通常会找 PSP(payment service platform)平台,它提供简单 API,我们直接调用,由其处理支付请求,当然会收取 0.5%到 1%的手续费。
支付系统设计目标
那为何还要设计支付系统?其实设计重点是记账和内部清算流程,即记录支付事实的系统,这让问题简单不少。
用户支付流程拆分
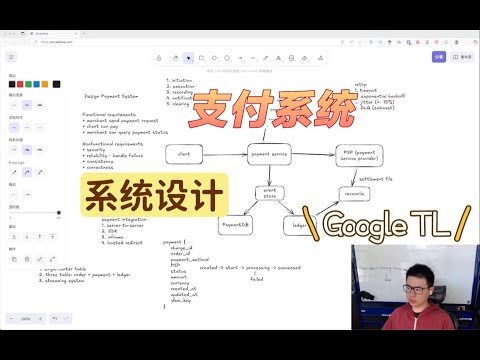
用户支付流程可拆分为以下步骤: 1. 商家发起支付请求。 2. 调用外部 PSP 的 API 执行支付请求。 3. PSP 执行后进行记录,记下账目。 4. 无论成功或失败,通知对应用户。 5. 每天进行账目清算。实际过程更复杂,但覆盖这些步骤基本足够,毕竟时间有限。
功能性与非功能性需求
功能性需求
功能性需求明确: 1. 商家能发起支付请求。 2. 客户能付费。 3. 商家能查看订单支付状态。
非功能性需求
非功能性需求包括: 1. 安全:与资金相关,security 是首要的。 2. 可靠性:能 handle 一些 failure。 3. 一致性:希望一笔钱只被扣款一次并正确记账。 4. 正确性:金融相关,确保账目永远正确。 5. 可扩展性:因调用外部 API,瓶颈多在外部,建议初期不考虑,有条件再研究。
支付集成方案
搞清楚需求后,画一个 high level 的 diagram。首先用户付款,商家服务器需提供付款逻辑,即支付集成,有多种方案:
Server to Server
商家从用户收集卡号和 CVV 密码,后端直接发给银行或卡网络,相当于自建 PSP,需取得支付机构牌照,一般不采用。因商家会接触 PAN 等敏感信息,需通过 PCI 审计,此过程复杂、合规门槛高且费用贵,技术复杂度和初期投入都高,基本只有大型企业使用。好处是通过 PCI 审计后自主权大,不依赖第三方支付平台,可省通道费,还能控制一些逻辑,如增加错误处理、分期、分账等。
引入支付平台 SDK
这是常见方案,如 stripe、paypal、微信、支付宝都提供。PSP 提供 js library,商家嵌入网站开发定制 UI,付费时 SDK 把用户卡号直接传到 PSP,返回 token,商家用 token 调用 PSP 的 API,不接触用户卡号,避免接触账号信息。但瓶颈在 SDK,若崩溃用户就不能付款。理论上 JavaScript SDK 通过 fetch() 送到 PSP 的 domain,不经过商家服务器,不过脚本在商家页面里,存在供应链攻击风险,商家需保护前端页面,采取安全策略,如 CSP 或 SRI,只允许加载可信脚本并验证哈希值,还可用 iframe 做更安全的 Sandbox 管理,隔离敏感数据减小攻击面。现在的 SDK 多采用混合模式,在底层注入 iframe,浏览器端用 iframe hosted field 隐藏银行卡信息,用 PSP 的公钥做 CSE 加密卡号,最后 Post 请求发到 PSP,PSP 解密返回不可逆 token,商家用 token 扣款。但 iframe 会限制前端 CSS 和响应式,对 UI 开发有影响,有能力的企业会基于 JavaScript SDK 二次开发,自由度高但成本也高。
Hosted Redirect
直接走托管支付页面,用户点击下单,302 跳转到 PayPal 或 Strape 等平台,付款后重定向回来。这是最简单的,PCI 负担和运维成本最低,出故障靠 PSP 兜底,但自由度最低,UI 和品牌都是 PSP 的,且多一步跳转,会损失用户转化率。
总之,可定制化越高,成本越高,不仅是技术实现成本,还有 PCI 责任和安全管控成本。
交易记录
集成支付系统后,商家如何记录交易?虽隔离了商家和用户银行卡信息,但用户提交付款信息后,PSP 会返回 token(也叫 nonce),后续扣款商家拿 nonce 向 PSP 发请求,nonce 一般一次性。有时商家问是否保存支付信息,勾选后商家会再请求换取可复用 token,这里只说单次 nonce。有这些信息后可写数据库,问题是怎么存。
数据库存储方案
第一个想法是用一张表存所有信息,每笔支付请求都记录,包括用户买的东西、金额、支付状态、卡号等,每条交易对应表中一条记录。但支付受合规限制,金融相关都需审计,支付数据不可更改,不能覆盖之前状态,最好拆分数据表。这里有三种状态: 1. 业务状态:有哪些订单,订单对应什么商品。 2. 交易状态:用户发起支付请求后是否付钱、用什么卡、付了多少、被拒绝还是成功。 3. 资金状态:钱是否到账、是否分配、多少给商家、多少给支付渠道手续费。
若做责任分离,至少三张数据表,读写模式不同,如资金状态表不可更改。对合规驱动业务的支付系统,多存一张表好过在同一张表改来改去。理论上可能需要 order table、payment table 和 ledger 账簿,核心是 payment,关注 payment 表数据结构。
Payment 表数据结构
假设这是 payment 表,可能需要以下字段: 1. charge ID 2. order ID 3. payment method 4. 对应的 PSP 5. 订单 status(创建支付请求、处理中、success 或 failed,通常用状态机表示) 6. 金额 7. 货币 8. 创建和更新时间 9. 用于幂等的 unique ID(idempotency key)
一致性处理
和金融相关要注意一致性,分内部和外部一致性。
内部一致性
用关系性数据库即可,其有一致性保障。
外部一致性
用户下单点击 checkout 开始支付,最怕 double charging 或 double spending,如用户网卡连点几次,服务器收到多个请求,不能都扣款,需实现 exactly once,这依赖 idempotency key。用户点开 checkout 页面时,服务器生成幂等键,后续流程都带此键。服务器把幂等键发给客户,客户下单后带键返回 payment service,service 端看到幂等键做 de-duplication,拦截重复请求,这样即使用户点多次,只有一个请求会被后续处理,处理时更新 payment 表的 status 状态。
状态机与重试机制
PSP 异步处理,我们不知何时处理好,通常 PSP 先给 200 表示已处理,若没信号(如网络抖动),应引入 retry 机制,需考虑四个要素: 1. timeout:retry 等待时间有最大限制,超此时间触发 retry。 2. backoff:决定间隔时间,推荐 exponential backoff,如第一次等 1 秒,第二次 2 秒,第三次 4 秒,依次类推,减少后端压力。 3. jitter:每次发请求加入网络抖动,如正负 15%,避免多个服务器同时发送请求给后端造成压力,使分布更均匀。 4. dead letter queue:设置最大重试次数,超次数视为后端 PSP 宕机,不再 retry,把消息放入死信队列处理,如本地回滚,可能还要熔断一段时间。
外部 PSP 也要做 de-duplication 操作,幂等键应同步穿透到 PSP,增加保险。PSP 返回提交成功消息后,先给用户返回信息,如“已下单”“等待确认”,PSP 会进一步处理,通常会给 PSP 一个 callback URL,PSP 处理完调用此 URL 通知我们,若调用失败,还需补上轮询,超过一段时间没收到 callback 主动查询。PSP 处理完,状态机进入 success 或 fail,通知用户,若进入 success 代表扣款成功,此时写 ledger,涉及账户、交易和分录建模,是复杂系统。
Ledger 相关
一般行业标准是商务实体采用复式记账,每笔交易至少影响两个账号,产生一组金额相等、方向相反的记录。ledger 有金融属性,写入后不可变,通常写入 append-only 的数据库,除关系型数据库外,针对 specific domain 可询问面试官是否有专用技术栈,如 amazon 的 QLDB 或 Alibaba 开源的 ledgerDB,都提供 SQL 接口并为金融事务优化,开发难度低,很多功能内置,如审计、加密等。
对账
任何在线链路都可能有 bug,银行应定时发 settlement file,我们每天执行对账任务,有问题触发自动补偿或转人工审核,这就是完整支付流程。但此流程有问题,如补的轮询,交易一直在审核,商家等不到 callback 开始轮询,轮询几次达上限写入 fail,之后 PSP 突然处理完调用 callback,此时应写入成功,这是状态机跳变。可使用单调状态机,进入 fail 后不能覆盖成 success,或打版本号补丁,每次更新比较版本号,最差等到日终对账环节,总之账目不能出错。问题根源是每次状态机变化对 paymentDB 的一条记录发起 UPSERT,覆盖之前状态,但多数 PSP 都用此方案,一张表维护实时操作状态,另一张账务表负责资金守恒,开发和维护成本低,方案成熟且合规。
其他方案
若进一步优化,存在另一种方案。之前讲过数据库和流系统互换案例,15 年有篇《Turning the database inside-out》,去掉数据库采用 event store,可用 Kafka、Apache Pulsar 等流系统或 append-only 的 db,也可两者都用。所有变更作为事件写入 event store,其作为 source of truth,再通过 projection 或 view 生成视图表加速查询,事件写入后不再更改,纠错以新事件方式写入冲正。不少互联网公司采用这种 ledger 系统,如 stripe、Coinbase、Square,以不可变账本加事件流形式,既保证金融系统正确性,又有互联网系统可拓展性,但系统复杂度高,开发和运维成本高,团队需熟悉流系统和金融系统,具体选型看场景。
接受流系统设定后,系统可有很多变化,如在前面放消息队列削峰填谷并数据落盘,Payment Service 作为 Broadcast 把每次事件投放到不同数据库,对账时在消息队列前端重放事件重新计算。若有时间,建议给面试官展示,如在 Payment Service 前面插入 Risk Engine 做 Fraud Detection,有多种方案,简单的可用规则引擎,如规则树、黑名单、白名单,便于合规和审计,但不适合复杂欺诈手段;常见的还可用统计学方式或简单机器学习模型,受限于数据,对新欺诈手段反应慢,需手动找特征和标注数据;大公司可能用无监督学习解决冷启动或零样本问题,但有误报率需人工审核;infrastructure 支持可上图模型或 GNN 捕捉复杂形式,这类系统维护和开发复杂,模型推断和开销大,但在金融风控中常见。
 {#
{#