高頻交易系統的速度追求
高頻交易系統追求的速度,不是毫秒級,而是微秒級甚至納秒級。在本影片中,我們將深入探討這些極速系統背後的實際架構。你將看到市場數據如何被接收、內存訂單簿如何運作、如何使用FPGA和策略引擎做出決策,以及如何在一眨眼的工夫將訂單路由到像納斯達克這樣的交易所。
什麼是高頻交易
高頻交易(HFT)的核心是使用算法和機器以極高的速度交易股票或期權等金融工具。我們所說的是每秒進行數千到數百萬筆交易,速度比人類眨眼還快。其目標是在每筆交易中獲得微小的利潤,有時只是一分錢的一小部分,但以如此高的交易量和速度進行,最終累積成巨大的收益。
這些系統尋找市場中的微小低效率,例如交易所之間的價格差異、訂單簿中的臨時失衡或緩慢的價格更新,並在其他人之前介入。但要做到這一點,速度就是一切。單個毫秒的延遲可能意味著賺錢和虧錢之間的差別。這就是為什麼高頻交易系統像賽車一樣被設計。從網絡卡到代碼的每個組件都針對超低延遲進行了優化。
高頻交易存在的原因
在金融市場中,先機至關重要。第一個對市場數據做出反應的系統可以利用它。其他人只能跟隨。例如,假設你正在運行一個做市策略。你不斷以9.99美元的價格下達買入訂單,以101美元的價格下達賣出訂單。現在,如果有人以101美元接受你的賣出訂單,你就賺了2美分的點差。現在,想象一下每秒在數百隻股票上進行數千次這樣的操作。
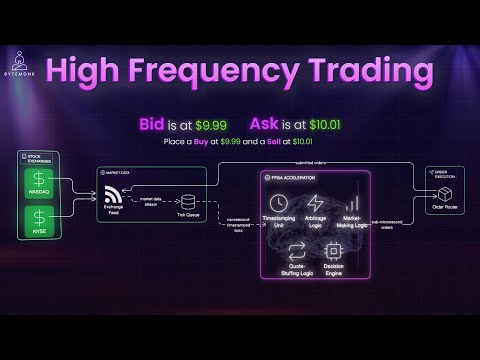
高頻交易管道的第一步:接收市場數據
高頻交易管道的第一步是接收市場數據。這是來自納斯達克和紐約證券交易所等證券交易所的價格、交易量和訂單簿更新的實時數據流。但我們所說的不是日常的API或websocket數據流。高頻交易系統使用直接通過超低延遲網絡傳遞的多播數據流,通常在靠近交易所服務器的託管設施內,以減少傳輸時間。
這些數據通過專用硬件——超低延遲NIC(網絡接口卡)和自定義TCP堆棧接收,有時甚至使用像DPDK或Solar Onload這樣的內核旁路機制。這些允許系統在微秒級處理市場更新,跳過常規網絡堆棧的開銷。
然後是市場數據饋送處理程序,這是一個關鍵組件,它傳遞原始流,解碼協議,並將其轉換為系統可以理解的格式。你可以將其視為交易所語言和內部邏輯之間的翻譯器。但它必須每秒翻譯數百萬條消息,不能有任何差錯。
更新訂單簿
一旦市場數據被接收和解碼,下一個關鍵步驟就是更新訂單簿。這是所有當前買入和賣出訂單的實時快照。高頻交易系統將整個訂單簿維護在內存中,以避免任何磁盤IO或數據庫延遲。它會隨著每個傳入的消息實時更新,觸發精確的更新。
在大多數系統中,你會看到複製的訂單簿,如複製A和複製B,使用內存複製保持同步。這確保了容錯性。因此,如果一個複製品崩潰或滯後,系統可以立即故障轉移到另一個。
訂單簿不僅用於記錄。它是推動管道其餘部分的動力。每個交易決策、每個做市策略都從訂單簿的當前狀態開始。這些更新然後被發布到事件流中,準備讓其他組件(如交易邏輯、FPGA引擎或智能路由器)以近乎零的延遲消費。
事件驅動管道
一旦訂單簿更新,新的市場狀態就會被發布到事件驅動管道中,這是高頻交易中實時處理的支柱。這個管道是圍繞一個針對吞吐量和低競爭進行了優化的無鎖循環構建的。為什麼是無鎖的?因為即使是由鎖定線程引起的最輕微的延遲也會影響交易時間。
每個事件,如價格變化或新的買入報價,都使用納秒精度的時鐘進行標記。這種級別的時間精度允許系統保持市場更新的確切順序,對內部組件的延遲進行基準測試,最重要的是與外部系統(如FPGA引擎和交易所)完美同步。結果是一個精確的時間戳市場事件流,下游系統(如交易策略、風險引擎或智能路由器)可以實時消費。
FPGA加速
現在我們進入管道中硬件優化程度最高的部分。FPGA加速。FPGA代表現場可編程門陣列。這是一種可重配置芯片,可以以硬件速度運行自定義邏輯,而無需CPU或操作系統的開銷。
在高頻交易中,FPGA用於即時執行。這意味著一旦一個市場事件到達,它就會被FPGA上的邏輯評估,並可以在亞微秒級的延遲內做出交易決策。為什麼這很重要?因為同樣,每個微秒都很重要。當CPU線程啟動時,FPGA已經評估了機會並發送了訂單。
這些FPGA通常直接連接到事件隊列,接收納秒時間戳事件,並運行預定義的交易策略。想想套利、做市或代碼填充,所有這些都被連接到硅片中。一些公司甚至更進一步。他們將整個決策邏輯推送到FPGA中,以完全繞過軟件。
當然,這也帶來了複雜性。FPGA代碼是用Verilog或VHDL編寫的,每個邏輯路徑都必須是確定性的。但如果做得正確,它可以讓你在市場中獲得最快的優勢。
軟件策略引擎
雖然FPGA處理超低延遲場景,但大多數交易邏輯仍然在基於軟件的策略引擎上運行。做市引擎監聽事件流,評估訂單簿的當前狀態,並做出快速決策。例如,我們應該收緊嗎?我們應該擴大點差嗎?還是我們應該撤銷我們的訂單?
假設最新的買入報價是9.99美元,最好的賣出報價是101美元。因此,你的引擎可能會以9.99美元買入,以101美元賣出,以捕捉點差,但它會根據市場走勢、波動性和庫存風險不斷重新計算。
這些引擎可以是基於規則的、統計的,甚至可以使用輕量級機器學習模型。但無論策略是什麼,重點都是速度和可預測性。
智能訂單路由器
一旦做出決策,訂單就會被推送到智能訂單路由器,它負責決定在何處以及如何執行,可能跨多個交易所。策略引擎是系統的大腦,但這個大腦以微秒級思考。
一旦交易策略決定下達訂單,它不會盲目地發送到交易所。它首先通過智能訂單路由器路由,該路由器決定在何處以及如何發送訂單以獲得最佳執行。它應該去納斯達克、紐約證券交易所,還是應該是市場訂單或限價訂單?
路由器根據流動性、延遲、成交概率甚至回扣結構實時評估多個場所。但在訂單發出之前,它會通過交易前風險檢查。這些對於防止金融災難絕對至關重要。
風險引擎確保你不會超支,訂單不會太大,並且策略不會因錯誤而失靈。這些檢查是自動化的,並在微秒級發生。如果有任何異常,訂單在到達交易所之前就會被阻止。
一旦通過檢查,智能路由器就會將訂單發送到選定的交易所,執行日志流回系統進行審計分析和學習。這個最後的檢查點確保速度永遠不會超越安全。
訂單管理系統
交易執行後,訂單管理系統(OMS)負責跟踪和鎖定一切。OMS保留了發送的訂單、狀態更新(如已成交、部分成交、已拒絕)、執行時間戳和所採取的路線的完整記錄。它就像交易平台的中樞神經系統,協調交易所、策略引擎和報告系統之間的通信。
監控和指標堆棧
與此同時,監控和指標堆棧並行運行,捕獲每個組件的延遲數據、系統健康狀況和性能指標。你通常會看到一個延遲儀表板,顯示從報價到交易的時間,指標收集器跟踪吞吐量、錯誤率和隊列深度,以及任何組件放緩或行為異常的警報。
所有這些對於事後交易分析、合規報告和持續優化都至關重要。在高頻交易中,即使是幾微秒的緩慢也可能導致錯過機會或重大損失。因此,實時監控不是可選的。它是競爭優勢的一部分。
從接收市場數據到做出瞬間決策並在微秒級執行交易,這是硬件加速、事件驅動軟件、納秒精度和無情優化的完美結合。所有這些都是為了消除每一個可能的延遲。
如果你對系統設計、低延遲工程感興趣,或者只是喜歡窺探高性能基礎設施的內部,請確保喜歡本影片,訂閱頻道,並點擊鈴鐺圖標,這樣你就不會錯過下一次深入探討。
嘿,在評論中告訴我,架構的哪一部分最讓你印象深刻。你想要更深入地了解策略邏輯、FPGA還是匹配引擎?下次見。