
系统设计面试中的取舍与任务调度系统设计
在真实的系统设计中,往往需要在多个方向上进行取舍,系统设计面试亦是如此。这就要求在时间管理和范围之间做出初步权衡。
澄清问题
-
系统性质:首先要明确任务调度系统是内部系统还是公开的外部系统。内部系统用户量通常在几万左右(约10k),而公开的外部系统用户可能超过百万。假设这里需要设计一个内部系统。
-
调度器类型:常见的调度器有Kubernetes、Spark(两层设计)、Linux的Cron Job等。由于面试时间有限,应优先解决最基础的问题,选择设计一个最小可行产品(MVP),即满足最小功能的最基础调度器。
-
任务类型:任务可能是一次性的脚本(临时任务),也可能是常驻的服务(如监听web的服务)。这里假设包含所有类型的任务。
功能需求
-
用户提交任务:用户可以提交各种类型的任务,包括短期的临时脚本和长期运行的服务。
-
查看任务结果:用户能够在仪表板上查看任务的执行结果。
-
高级特性:
-
定时任务:用户可以安排未来的任务,如每30分钟查邮件或每天晚上12点进行数据库备份(Cron Service)。
-
任务依赖:对于数据分析业务,可能存在任务依赖,形成有向无环图(DAG)任务。
-
非功能需求
-
延迟要求:用户提交任务后,系统应在10秒内开始执行。仪表板同步任务结果应在60秒内完成。
-
可扩展性:系统可能会处理大量任务,需要具备可扩展性。
-
可靠性:异步执行任务时,若系统挂掉后重新拉起,需要能重新捡起任务继续执行。
数据模型设计
一个可执行的任务数据模型应包含两部分:
-
可执行文件或配置文件:存储在单独的仓库中,可抽象为二进制文件。
-
元数据:包括任务ID、所有者ID、可执行文件的二进制URL、输入输出路径、创建时间、执行结果、重试次数等。
状态转换设计
设计一个简单的状态转换机:
-
初始状态:任务从“ready”开始。
-
提交后:进入“waiting”状态。
-
执行结果:执行可能成功,也可能失败。失败后若重试次数小于3次,进入“retry”状态,回到“waiting”等待下一次执行;若重试次数大于等于3次,进入“final failed”状态。
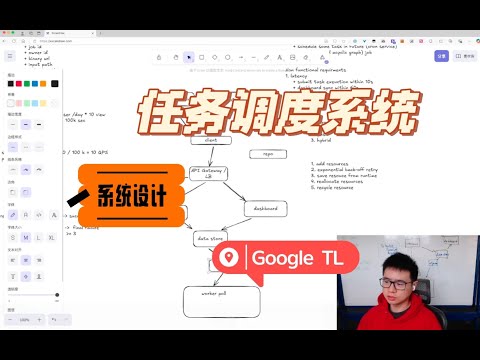
高层架构设计
-
存储:需要一个独立的仓库来保存代码或可执行的二进制文件,如AWS S3之类的存储桶。
-
任务提交:客户端提交任务请求到“submission”,“submission”将任务保存到“datastore”。
-
任务执行:“worker”从“datastore”获取任务执行,为了解耦,可加入一个“queue”。
-
仪表板:从“datastore”读取任务执行状态。若QPS较高,可在“dashboard”和“datastore”中间加一个缓存,TTL设为60秒。
经计算,该内部系统的QPS较低,初步设计时缓存可能没有必要。
深入探讨
-
数据存储:考虑到单机数据库可能存在单点故障风险,可采用主从结构进行读写分离,甚至双主结构形成双机热备。NoSQL也是一个可选项,具体取决于数据模型、查询模式和一致性要求。若没有强信号表明需要关系型数据库,可推迟决策,遵循开闭原则。
-
消息队列:使用消息队列进行削峰填谷,解耦上下游的执行和提交。但要考虑队列类型,内存队列扩容方便但数据可能丢失,磁盘队列数据不丢失但扩容麻烦。从更高角度看,引入两个数据系统(数据存储和队列)存在数据一致性问题,可考虑只使用一套数据系统,如将消息队列作为数据存储(如Kafka作为数据库)或数据存储作为消息队列(如Google的Spanner Queue)。
-
任务分发:有三种方案:
-
Worker发起RPC:Worker发起RPC拉取任务运行,运行完写回状态到“datastore”。好处是“Informer”管理简单,但Worker会不停轮询,95%时间可能空转,且Worker权限较大不安全,还可能因Worker挂掉导致状态无法更新。
-
Informer发起RPC:Informer将任务推给Worker并跟踪状态。好处是隔离了Worker,只有有任务时才启动Worker,还能定期查询Worker状态并在其挂掉时拉起新的Worker。坏处是Informer需要长期追踪Worker状态,可能需要额外建立长链接并知道每个task对应Worker的地址。
-
混合模型:Informer将任务推给Worker,Worker搭载sidecar监控运行状态,每隔60秒发送一次心跳包。好处是融合了前两种方案的优势,既安全又避免了Worker直接发起RPC,Informer也无需维护task和Worker的映射。坏处是增加了每个worker的开销。
-
资源管理
-
资源紧张应对:
-
增加资源:直接加机器添加更多资源。
-
指数退避重试:在资源紧张只是暂时的情况下,可增加等待时间,如第一次失败等待1秒重试,第二次等待2秒,第三次等待4秒。
-
节约资源:
-
运行时优化:将虚拟机换成容器以节约资源,但要注意容器暴露的攻击面,可使用gVisor保证安全;或者裁剪虚拟机,如Google的no-vm或AWS的firecracker。
-
调度优化:从工作负载隔离转向混合部署,提高机器利用效率,但需要开发特殊的调度算法。
-
资源回收:通过回收用户申请但未充分利用的资源来压榨性能,如Google的AutoPilot和腾讯的GoCrane项目。对于常驻的生产服务要优先保证高可用性,对于可抢断的临时任务,在资源紧张时可考虑延后或压缩资源。
-
-
功能拓展
-
定时任务支持:将客户端封装成库,上层接入Cron Service,维护一个按任务下次运行时间排序的优先级队列,提交定时任务并按时间顺序弹出任务发送给Task Scheduler的Client端。
-
DAG任务支持:添加DAG Service Scheduler,将DAG任务丢给该服务,在内存中进行拓扑排序,按顺序提交任务给Task Client,等待返回Success信号后提交下一个任务。可选择将优先级队列和拓扑排序部分放在Informer内存中,或作为单独的Service,各有优缺点,最终方案取决于使用场景。
 {#
{#