
Introduction
In a real-world system design, trade-offs are often made in several directions. System design interviews are no different. You need to make a preliminary trade-off between Time Management and Scope. This article focuses on the system design of a task scheduling system.
Clarifying Questions
Internal or External System
-
Internal System: Usually has around 10,000 users.
-
External System: Can have over a million users.
-
For this discussion, we assume an internal system as it offers more points to explore.
Type of Scheduler
-
There are several types, such as Kubernetes scheduler, Spark scheduler (with a two-layer design), and Linux Cron Job.
-
Given the limited time (less than an hour), we need to decide on the type of scheduler. It's crucial to focus on the minimum viable product (MVP) to meet the basic functionality.
Task Types
-
Temporary Tasks: Like running a script once and then discarding it.
-
Long-Run Services: Such as monitoring a web service and running continuously.
-
We assume the system will handle both types of tasks, i.e., jobs can be of all types.
Functional Requirements
-
Task Submission: Users can submit tasks, which can be short-term temp scripts or long-run services.
-
Task Result Viewing: Users can see the task execution results on a dashboard.
-
Advanced Features:
-
Scheduling tasks in the future.
-
Setting up cron services for periodic tasks.
-
Handling job dependencies in a Directed Acyclic Graph (DAG) structure, common in data analysis tasks.
-
Non-Functional Requirements
-
Latency:
-
Task execution should start within 10 seconds of submission.
-
Dashboard should sync and show results within 60 seconds.
-
-
Scalability: The system should be able to handle a large number of tasks.
-
Reliability: In case of system failure, tasks should be picked up and resumed when the system restarts.
Data Model Design
A job data model should include:
-
Repository: Stores executable files or configuration files, which can be abstracted as a binary file.
-
Metadata:
-
Job ID.
-
Owner ID.
-
URL of the executable binary file.
-
Input and output paths.
-
Created time.
-
Execution result and number of retries.
-
State Transition Design
-
Ready State: The initial state of a task.
-
Waiting State: After task submission.
-
Execution State: Has two possible outcomes - success or failure.
-
If the task fails and the number of retries is less than three, it goes back to the waiting state for retry.
-
If the number of retries reaches or exceeds the threshold, it enters the final failed state.
-
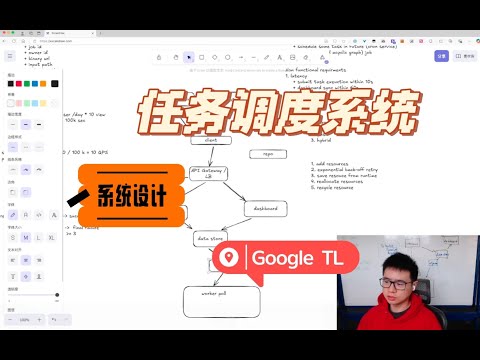
High-Level Architecture Diagram
-
Repository: Stores code or executable binary files, such as an AWS S3 bucket.
-
Client: Submits task requests to the submission component.
-
Submission: Saves the task in the datastore.
-
Queue: Decouples the submission and execution processes. Workers can fetch tasks from the queue.
-
Worker: Executes tasks retrieved from the queue.
-
Dashboard: Reads task execution status from the datastore. If the QPS is high, a cache with a 60-second TTL can be added between the dashboard and the datastore.
Deep Dive
QPS Analysis
-
For an internal system with 10,000 users submitting 100 jobs per day, the QPS for task submission is around 10, and the peak QPS is about 50.
-
For viewing task results on the dashboard, the QPS is around 100, with a peak of 500. Given these relatively low QPS values, adding a cache may not be necessary in the initial design.
Datastore Considerations
-
Single Database: Can handle the low QPS, but it's a single point of failure.
-
Master-Slave or Dual-Master Structure: Can provide redundancy and improve reliability.
-
NoSQL vs. SQL:
-
There is no strong signal favoring either relational or NoSQL databases.
-
Factors to consider include data model (foreign key support), query pattern (join queries), and consistency requirements.
-
Since there are no strong requirements for these factors and the latency tolerance is relatively high, both NoSQL and SQL are viable options. It's advisable to defer this decision to follow the开闭原则 in clean architecture.
-
Message Queue
-
Purpose: To decouple the upstream submission and downstream execution processes and handle peak loads.
-
In-Memory vs. In-Disk Queue:
-
In-memory queue is stateless and easy to scale but may lose data.
-
In-disk queue persists data but is more complex to scale.
-
-
Data System Complexity: Using two data systems (datastore and queue) may introduce complexity. We can consider alternatives such as using a message queue as a data storage or vice versa.
-
Message Queue as Data Storage: For example, using Kafka as a database. It's technically feasible and has low latency but may increase engineering complexity and operation costs.
-
Data Storage as Message Queue: For example, Google's Spanner Queue. It's also feasible and more widely accepted, but may have lower single - machine performance. However, this can be addressed through sharding.
-
Worker and Informer Communication
Pull Model
-
Worker initiates RPC to pull a task from the informer, executes it, and writes the result back to the datastore.
-
Advantage: Informer doesn't need to manage much.
-
Disadvantages: High idle time, security concerns due to worker's high权限, and potential state update issues if the worker fails.
Push Model
-
Informer initiates RPC to push a task to the worker and tracks the state.
-
Advantage: Isolates the worker and only starts it when there is a task.
-
Disadvantage: Informer needs to maintain long-term tracking of the worker's state and establish long-term connections.
Hybrid Model
-
Combines the advantages of the pull and push models. Informer pushes the task, and a sidecar on the worker monitors its state and sends heartbeats every 60 seconds.
-
Advantage: Secure and reduces the complexity of informer's task - worker mapping.
-
Disadvantage: Adds overhead to each worker.
Resource Management
Resource Shortage
-
Short-Term Solutions:
-
Add resources (machines).
-
Implement exponential back-off retry.
-
-
Long-Term Solutions:
-
Runtime Optimization: Replace virtual machines with containers for lightweight execution, but additional security measures like gVisor may be needed. Or use lightweight virtual machines like Google's no - vm or AWS's firecracker.
-
Scheduling Optimization: Move from workload isolation to hybrid deployment to improve resource utilization, but this requires developing special scheduling algorithms.
-
Resource Recycling: Recycle over - requested resources. Google's AutoPilot and Tencent's GoCrane are examples of projects that do this. For preemptive tasks like temporary database backups, resource compression or delay can be considered during resource shortages.
-
Advanced Features
Cron Service
-
Encapsulate the client as a library.
-
Add a Cron Service on top that maintains a priority queue sorted by the next run time of each job.
-
Users can submit cron tasks to the Cron Service, which inserts them into the priority queue and triggers task execution when the time arrives.
DAG Service
-
Add a DAG Service Scheduler on top.
-
Perform topological sorting on DAG tasks in memory and submit them to the Task Client in order.
-
Wait for a success signal from the client before submitting the next task.
-
Trade-off: Keeping the priority queue and topological sorting in the informer's memory reduces the need for additional services but increases the complexity of the informer. Separating them as individual services reduces complexity but adds overhead and improves scalability.
The final design choice depends on the specific usage scenario.
 {#
{#